Introduction to NoSQL

Table of Contents
NoSQL
Centralized Systems
Centralized systems operate with a single node (server) handling all tasks. Here are the key characteristics:
- Single Node Operation: One node executes the same task, making the system simpler but less scalable.
- Data Storage: Related data is always stored on the same node, ensuring easy access but limiting data handling capacity.
- ACID Properties: These systems adhere to the ACID (Atomicity, Consistency, Isolation, Durability) properties, ensuring reliable transactions.
- Independence of Nodes: No inter-node management is required, as nodes operate independently.
- Limitations with Big Data: Centralized systems struggle with handling large volumes of data.
- Performance Constraints: Performance tuning is limited, and the system requires more time to process tasks because:
- All data must be scanned due to the absence of partitioning.
- Access management becomes increasingly complex as data and users grow.
Distributed Systems
Distributed systems leverage multiple nodes to perform tasks. Key features include:
- Multiple Node Operation: Tasks are distributed across several nodes, enhancing scalability and fault tolerance.
- Distributed Data Storage: Related data can be scattered across multiple nodes, allowing for better data management and access speed.
- CAP/PACELC Theorem: These systems follow the CAP (Consistency, Availability, Partition Tolerance) or PACELC (Partition tolerance, Availability, Consistency Else Latency, Consistency) theorems, balancing trade-offs in performance and reliability.
- Management Requirements: Requires sophisticated management for consistency, replication, and fault tolerance.
- Handling Big Data: Capable of managing large data volumes effectively.
- Performance Optimization: Performance can be fine-tuned through CAP trade-offs, offering flexibility in system behavior.
- Efficiency in Task Fulfillment: Distributed systems require less time to complete tasks because:
- Data is sharded and replicated across multiple servers, facilitating faster access and processing.
- Access management can be simplified, depending on the consistency model chosen.
Scaling
Vertical Scaling
Vertical scaling involves enhancing the capacity of a single node by upgrading its hardware. Key points include:
- Applicability: Particularly effective for centralized systems but can also be applied to distributed systems.
- Hardware Limitations: There is a finite limit to vertical scaling, constrained by the most advanced available hardware.
- Performance Boost: Improves performance by increasing the node’s processing power, memory, or storage.
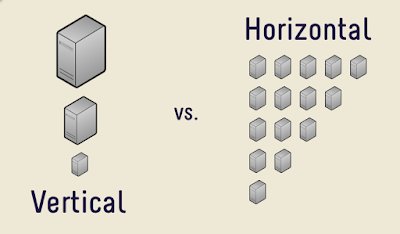
Horizontal Scaling
Horizontal scaling involves adding more nodes to the system to distribute the workload. Important aspects are:
- Distributed Systems: Primarily used in distributed computing environments.
- Scalability: There is no inherent limit to horizontal scaling; additional nodes can always be added.
- Fault Tolerance and Load Balancing: Enhances system reliability and efficiency by spreading the load across multiple nodes.
Combined Scaling
Both vertical and horizontal scaling can be used together to optimize performance:
- Enhanced Flexibility: Combining both scaling methods allows for greater flexibility and optimization.
- Comprehensive Performance Improvement: Utilizing both strategies can address the limitations of each, providing a more robust and scalable system.
NoSQL Databases
Definition
NoSQL stands for “Not Only SQL.” This designation highlights that while NoSQL databases may include query languages, they are distinct from traditional SQL databases. Key characteristics include:
- Non-relational Structure: NoSQL databases are schemaless and designed to avoid join operations.
- Designed for Distribution: Although they can be hosted as single-node systems, they are optimized for multi-node (distributed) computation.
- Horizontal Scaling: NoSQL databases inherently support horizontal scaling, enabling them to handle large-scale data efficiently.
- Broad Categorization: Any database that does not follow a relational model is categorized as NoSQL.
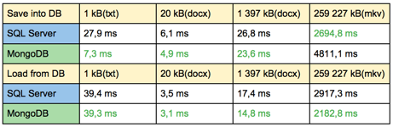
Performance and Use Cases
NoSQL databases offer performance advantages in specific scenarios due to their consistency models and design optimizations:
- Read-Operations and Small Transactions: They are highly performant for read-heavy operations and small transactions.
- Big Data and Data Analytics: Optimized for fast reading of huge datasets, making them ideal for big data computation and analytics.
- Business Applications: Less suitable for applications requiring complex relations with numerous write operations, as they are not optimized for such use cases.
CAP-Theorem
Definition
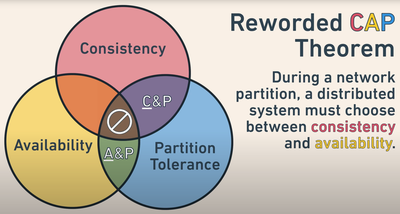
The CAP-Theorem, relevant for NoSQL databases, provides a framework analogous to the ACID theorem for relational databases. ACID properties are not applicable to NoSQL databases, necessitating the use of the CAP theorem. CAP stands for:
- Consistency: Ensures that if one node has updated data (e.g., version v2), all other nodes should reflect this updated version.
- Availability: The system must always be operational, minimizing downtime and locks.
- Partition Tolerance: The system should continue to function even if parts of the network fail.

Theoretical Limitations
In theory, a distributed system can only satisfy two of the three CAP properties simultaneously:
Consistency and Partition Tolerance (CP):
- The system maintains consistent data across nodes by locking nodes to ensure the same data version on all nodes.
- This approach sacrifices availability because multiple nodes may become unavailable during data synchronization.
Availability and Partition Tolerance (AP):
- The system remains operational and accessible on all nodes, ensuring minimal downtime.
- This approach sacrifices consistency, as there is no guarantee that all nodes will have the most recent data version.
Consistency and Availability (CA):
- This combination is only feasible in centralized systems.
- For distributed systems, achieving both consistency and availability without partition tolerance is impossible.

PACELC-Theorem
Definition
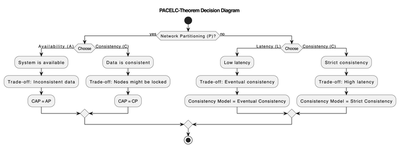
The PACELC-Theorem extends the CAP theorem by addressing system behavior not only during network partitioning (P) but also under normal operation conditions (E). It states:
- During Partitioning (P): The system must choose between Availability (A) and Consistency (C), aligning with the CAP theorem.
- Else (E): When there is no partition, the system must choose between Latency (L) and Consistency (C).
Key Concepts
- Latency vs. Consistency:
- Increased consistency typically results in higher latency because nodes need to synchronize data, causing delays.
- Decreased latency can be achieved by sacrificing consistency, where responses are quicker but may not reflect the most recent data.
Consistency Models
There are two primary consistency models to understand:
Strict Consistency (EC - Eventual Consistency):
- Guarantees the most recent data regardless of which node is accessed.
- Nodes may be locked when new data is available, causing temporary unavailability and increased latency.
Eventual Consistency (EL - Eventual Latency):
- Data may differ between nodes at any given moment (t = n).
- After a certain period (x seconds), all nodes will converge to the same data state.
- Nodes are not locked when new data is available, ensuring lower latency but with a temporary inconsistency.
Practical Implications
- AP or CP Systems: While systems are often labeled as AP (Available and Partition-tolerant) or CP (Consistent and Partition-tolerant), they can still be fine-tuned for latency and consistency during normal operation.
- Tunable Consistency: The trade-off between latency and consistency can be adjusted to meet specific application requirements.
Replication & Sharding
Definition
Replication and sharding are key strategies for data management in distributed systems, designed to improve performance and reliability.
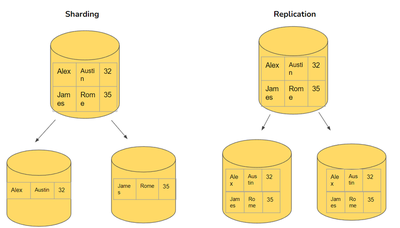
Sharding
Sharding involves splitting data across multiple nodes, often partitioned by a key. Key points include:
- Partitioned Data: Data is divided into distinct shards, each stored on different nodes.
- Efficient Data Retrieval: The system reads only the relevant partition, improving query efficiency.
- Load Balancing: Different users access different shards, automatically distributing the load.
- Performance Enhancement: Large datasets can be processed in parallel across multiple servers, enhancing performance.
Replication
Replication involves copying the same data across multiple nodes. Key points include:
- Data Redundancy: Ensures that data remains available even if some nodes fail.
- Improved Availability: Multiple nodes can serve the same data to different users, reducing access times.
- Load Distribution: Balances the load by allowing multiple nodes to handle requests for the same data.
Combined Use
Both replication and sharding can be used together or separately:
- Strategic Implementation: Combining both strategies can provide a robust solution but must be carefully planned to avoid excessive overhead.
- Performance Optimization: Over-sharding or over-replicating can decrease performance due to increased management complexity. A balanced approach is essential.
Implementing these strategies effectively requires careful planning to determine the optimal number of shards and replications, ensuring improved performance without unnecessary overhead.
Refresher: RDBMS
Relational Approach, Schema, and Relationships
Relational Database Management Systems (RDBMS) store and organize data using a relational model. In this model, data is structured into tables (also called relations), which consist of rows and columns. Each table represents a specific entity type (such as customers or products), and each row represents a record, or instance, of that entity.
Schema defines the structure of these tables in a database. It specifies the columns in each table, along with their data types, and sets the constraints like primary keys, foreign keys, and unique constraints that uphold data integrity.
Relationships describe how tables relate to each other. The primary types of relationships are:
- One-to-Many (1:N): A record in one table can be associated with one or more records in another table. For example, a customer can have multiple orders.
- Many-to-One (N:1): Many records in one table are associated with a single record in another table. This is essentially the reverse of a one-to-many relationship.
- Many-to-Many (N:N): Records in one table can be associated with multiple records in another table and vice versa. This is typically implemented using a join table that includes foreign keys referencing the primary keys of the two tables being linked.
Normalization (1NF, 2NF & 3NF)
Normalization is a process in database design to reduce redundancy and improve data integrity. It involves decomposing a table into smaller tables without losing data.
- First Normal Form (1NF): Requires that all table columns contain atomic and unique data, and values in each column are of the same data type.
- Second Normal Form (2NF): Achieved when it is in 1NF and all non-key attributes are fully functionally dependent on the primary key.
- Third Normal Form (3NF): Met when it is in 2NF and all the columns are only dependent on the primary key, not on any other non-key attributes.
Joins
Joins are used to retrieve data from multiple tables based on logical relationships among them. Each type of join determines how rows from each table are combined and which rows are returned.
- LEFT JOIN: Used to return all records from the left table and matched records from the right table. If there is no match, the result is NULL on the side of the right table.
- INNER JOIN: Shows only those records that have matching values in both tables.
- RIGHT JOIN: Returns all records from the right table, and the matched records from the left table. If there is no match, the result is NULL on the side of the left table.
- FULL OUTER JOIN: Returns records when there is a match in either the left or right table. Records that do not match are also included, with NULLs in place where data is missing.
This refresher on RDBMS highlights foundational concepts that are essential for managing data in relational databases effectively, ensuring data consistency and enabling efficient data retrieval and manipulation through SQL queries.
Task 1&2 RDBMS Schema & NoSQL
Types of NoSQL Databases
NoSQL databases offer flexible schemas and are designed to handle a wide variety of data types. Unlike traditional relational databases, NoSQL databases do not rely on a fixed schema, making them suitable for unstructured and semi-structured data. Here are the four main types of NoSQL databases:
Column-Family Stores
Column-family stores organize data into columns instead of rows. Each column family contains rows, and each row can have multiple columns. This structure allows for highly efficient read and write operations and is particularly useful for handling large volumes of data across distributed systems.
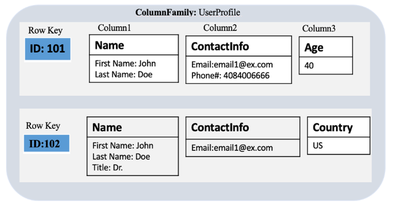
- Example: Apache Cassandra, HBase
- Use Case: Real-time data processing, time-series data
Key-Value Stores
Key-value stores use a simple key-value pair mechanism to store data. Each key is unique and is used to retrieve the corresponding value. This type of database is highly performant and can handle massive amounts of data with minimal latency.
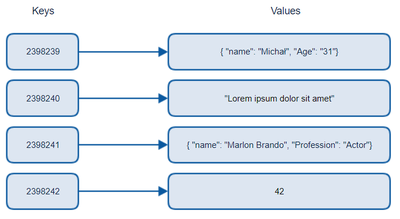
- Example: Redis, DynamoDB
- Use Case: Caching, session management, real-time analytics
Graph Databases
Graph databases are designed to efficiently store and query data that is highly interconnected. They represent data using three main components:
- Nodes: These are the entities or data points. For example, in a social network, each person would be a node.
- Edges: These are the relationships between the nodes. In a social network, an edge might represent a friendship or a follow relationship. Edges can also have properties and directions, indicating the type and nature of the relationship.
- Properties: These are additional information associated with nodes and edges. For instance, a node representing a person might have properties like name and age, while an edge representing a friendship might have a property indicating the date the friendship started.
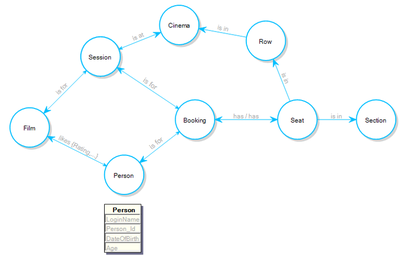
- Example: Neo4j, Amazon Neptune
- Use Case: Social networks, recommendation engines, fraud detection
Document Stores
Document stores manage data in the form of documents, typically using formats like JSON, BSON, or XML. Each document is a self-contained unit, which can store complex nested structures. This allows for greater flexibility and easier mapping to object-oriented programming languages.

- Example: MongoDB, CouchDB
- Use Case: Content management systems, e-commerce applications, mobile app data storage
Relational vs. NoSQL Databases
Relational Databases:
Store data in tables with rows and columns. Each row represents a record, and each column represents an attribute. In a row-oriented database, every row is scanned regardless of which columns are required.
Relational vs. Column-Based Databases
Column-Based Databases:
Store each column separately, allowing for quicker scans when only a small number of columns are involved. This approach is beneficial for analytical queries where only specific columns are needed.
Key Differences:
Relational databases are row-oriented, making them efficient for transaction processing where multiple attributes of a single record are accessed. Column-based databases allow for faster scans of individual columns, improving performance for analytical queries.
Relational vs. Key-Value-Based Databases
Key-Value-Based Databases:
Store data as key-value pairs, where each key is unique and maps directly to a value. The value can be a simple data type or a complex object, enabling extremely fast lookups.
Key Differences:
Relational databases are suitable for complex queries and transactions, such as those in banking systems. Key-value databases are ideal for quick access scenarios like caching and session management. Their simplicity makes them highly scalable and efficient for real-time analytics.
Relational vs. Graph-Based Databases
Graph-Based Databases:
Designed to store and manage highly interconnected data. They consist of:
- Nodes: Entities, such as people in a social network.
- Edges: Relationships between entities, which have properties and can be directed. For example, an edge might indicate who follows whom and include properties like the date the relationship started.
Key Differences:
Relational databases are suitable for structured data with complex queries and transactions. Graph databases excel in scenarios with highly interconnected data, such as social networks, scientific citations, or asset management. They efficiently store relationships with properties, allowing for fast and complex queries involving traversals and connections between entities.
Task 3 LinkedIn Post
Show how this LinkedIn Post would be stored in a Document-DB: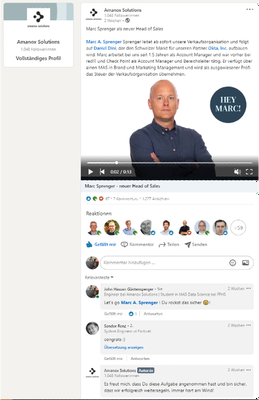
{
"id": "post_001",
"company": {
"name": "Amanox Solutions",
"followers": 1048,
"profile_url": "/companies/amanox-solutions"
},
"author": {
"name": "Marc Sprenger",
"title": "Head of Sales",
"profile_url": "/in/marcsprenger"
},
"content": {
"text": "Marc A. Sprenger leitet ab sofort unsere Verkaufsorganisation und folgt auf Daniel Dini, der den Schweizer Markt für unseren Partner Oktak, Inc. aufbauen wird. Marc arbeitet bei uns seit 1,5 Jahren als Account Manager und war vorher bei redIT und Check Point als Account Manager und Bereichsleiter tätig. Er verfügt über einen MAS in Brand und Marketing Management und wird als ausgewiesener Profi das Steuer der Verkaufsorganisation übernehmen.",
"media": {
"type": "video",
"url": "/posts/marc-sprenger-video",
"duration": "0:13"
}
},
"engagement": {
"likes": 67,
"comments": 7,
"views": 1277
},
"comments": [
{
"author": "John Hassan Güntensperger",
"profile_url": "/in/johnhassan",
"text": "Let's go Marc A. Sprenger! Du rockst das sicher! 😀",
"date": "2 Wochen zuvor"
},
{
"author": "Sandor Reng",
"profile_url": "/in/sandorreng",
"text": "congrats :)",
"date": "2 Wochen zuvor"
},
{
"author": "Amanox Solutions",
"profile_url": "/companies/amanox-solutions",
"text": "Es freut mich, dass Du diese Aufgabe angenommen hast und bin sicher, dass wir erfolgreich weitersegeln, immer hart am Wind!",
"date": "2 Wochen zuvor"
}
]
}
---